TK教主的学习方法论
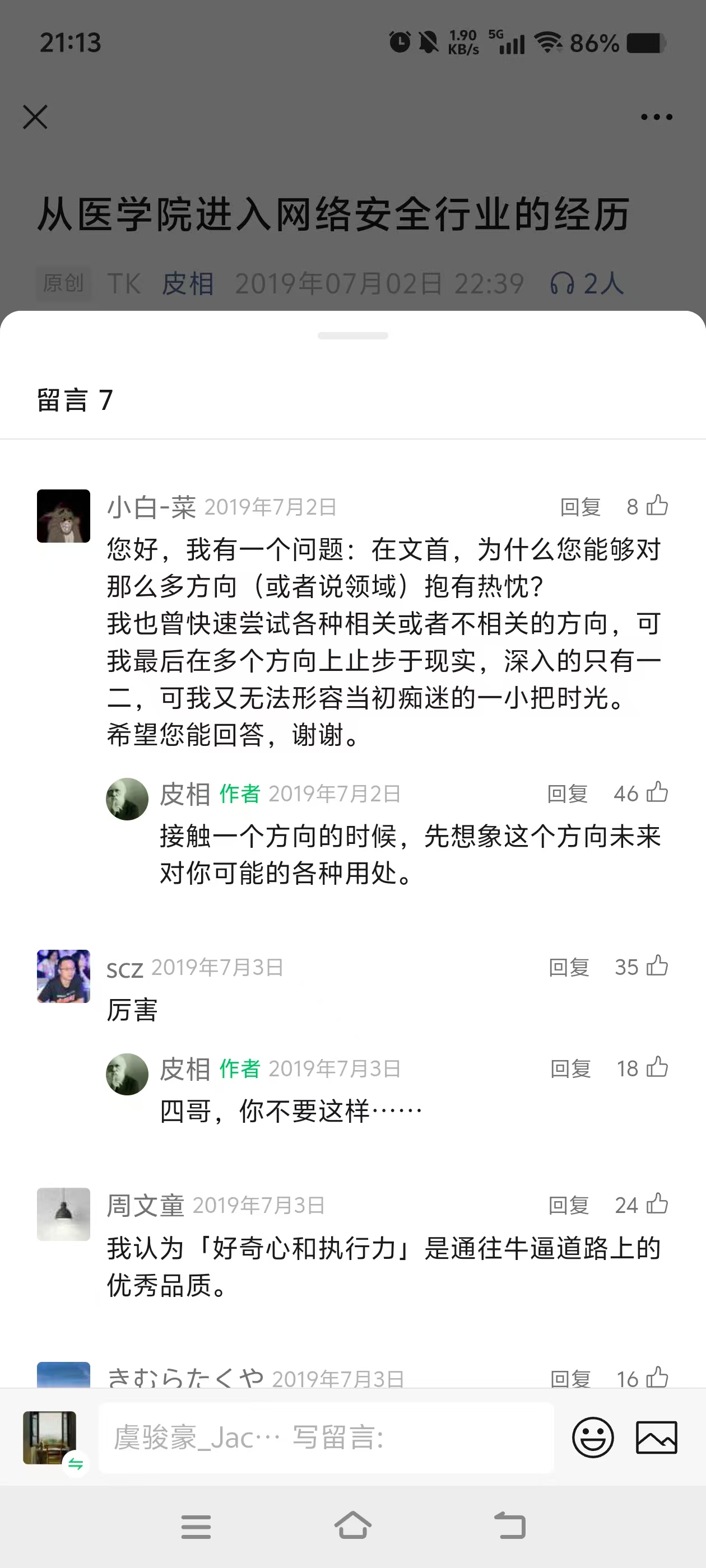
起心动念来源:tk教主的个人公众号皮相文章 - [从医学院进入网络安全行业的经历] https://mp.weixin.qq.com/s/FRomJ-mfbFKpjyweEC1tOw 评论区 网友きむらたくや 的发言 教主是国内安全圈我最佩服的人了,对其思想高度、知识广度和学习方法印象深刻。这里分享下教主的学习方法论,拿走不谢:https://blog.csdn.net/weixin_34402408/article/details/87495530(这个链接已经无法正常访问,于是上网主动搜索,发现网络上有很多网友做了备份)。下面是其中一个,和大家分享:
- [evernote-wiki/1/TK 的学习方法论.md at master · HiAwesome/evernote-wiki] https://github.com/HiAwesome/evernote-wiki/blob/master/1/TK%20%E7%9A%84%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95%E8%AE%BA.md
总览
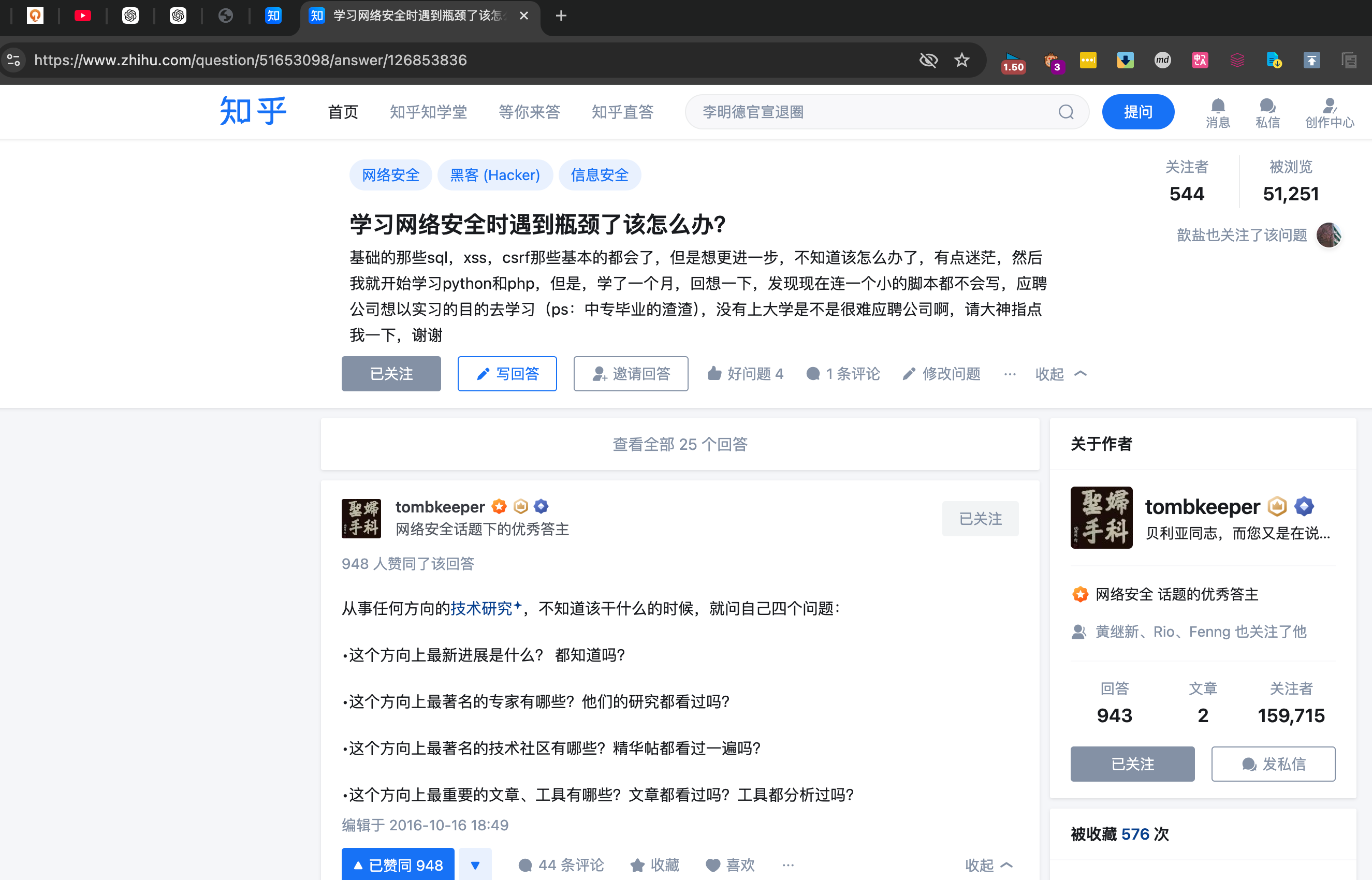
来源于 TK教主 的[一条微博] https://weibo.com/1401527553/FacHzEHFb 和 [一个知乎回答]https://www.zhihu.com/question/51653098/answer/126853836。
皮相 作者(tk教主) 2019年7月2日 回复 网友 接触一个方向的时候,先想象这个方向未来对你可能的各种用处。


个人成长
- 确立个人方向,结合工作内容,找出对应短板
- 该领域主要专家们的工作是否都了解?
- 相关网络协议、文件格式是否熟悉?
- 相关的技术和主要工具是否看过、用过?
- 阅读只是学习过程的七点,不能止于阅读
- 工具的每个参数每个菜单都要看、要试
- 学习网络协议要实际抓包分析,学习文件格式要读代码实现
- 学习老漏洞一定要调试,搞懂别人代码每一个字节的意义,之后要完全自己重写一个 Exploit
- 细节、细节、细节,刨根问底
建立学习参考目标
- 短期参考什么?比自己优秀的同龄人
- 阅读他们的文章和其他工作成果,从细节中观察他们的学习方式和工作方式
- 中期参考什么?你的方向上的业内专家
- 了解它们的成长轨迹,跟踪他们关注的内容
- 长期参考什么?业内老牌企业和先锋企业
- 把握行业发展、技术趋势,为未来做积累
推荐的学习方式
- 以工具为线索
- 一个比较省事的学习目录:Kali Linux
- 学习思路,以 Metasploit 为例:
- 遍历每个子目录,除了 Exploit 里面还有什么?
- 每个工具分别有什么功能?原理是什么?涉及哪些知识?
- 能否改进优化?能否发展、组合出新的功能?
- 以专家为线索
- 你的技术方向里有哪些专家?
- 他们的邮箱、主页、社交网络账号是什么?
- 他们在该方向上有那些作品?发表过哪些演讲?
- 跟踪关注,一个一个学。
处理好学习、工作和生活
- 学习、工作和生活是矛盾统一的
- 三者都需要时间,你一天只有 24 小时:调和矛盾的关键:提高效率
- 对没有一个好爸爸的人来说,你的学习、工作会影响你能不能追求诗和远方
- 有好爸爸也要学习,因为能力之外的资本等于零。(图为王思聪微博:SAT 不是满分我们一般都没脸说过考过)
如何提高效率
- 做好预研,收集相关前人成果,避免无谓的重复劳动
- 在可行性判断阶段,能找到工具就不写代码,能用脚本语言写就不要用编译语言,把完美主义放在最终实现阶段
- 做好笔记并定期整理,遗忘会让所有的投入都白白浪费
- 多和同事交流,别人说一个工具的名字可能让你节约数小时
- 咖啡可以提高思维效率,而且合法
- 无论怎么提高效率,要成为专家,都需要大量的时间投入
方向缺失解决方案
从事任何方向的技术研究,不知道该干什么的时候,就问自己四个问题:
- 这个方向上最新进展是什么?都知道吗?
- 这个方向上最著名的专家有哪些?他们的研究都看过吗?
- 这个方向上最著名的技术社区有哪些?精华帖都看过一遍吗?
- 这个方向上最重要的文章、工具有哪些?文章都看过吗?工具都分析过吗?
Chatgpt:将TK教主的学习方法迁移到我的Python爬虫学习中,可以结合以下策略:
1. 确立个人方向和短板
-
目标明确: 你的目标是成为能独立完成爬虫任务的开发者,比如掌握网站数据抓取、反爬技术应对和数据清洗。
-
短板识别
:
结合课程内容,找出你目前薄弱的地方。例如:
- 是否熟悉Python中的爬虫框架(如
requests、BeautifulSoup、Scrapy)? - 是否理解HTTP协议、Session机制、Cookies工作原理?
- 是否掌握反爬技术(验证码破解、动态渲染处理)?
- 是否熟悉Python中的爬虫框架(如
2. 阅读只是起点,实践为核心
-
工具细节
:
- 学习爬虫相关工具和库(如
requests、Selenium),每个功能、每个参数都要尝试。 - 用Wireshark抓包分析请求,理解HTTP通信。
- 实验性地爬取不同类型的网站(静态/动态/反爬措施强的网站)。
- 学习爬虫相关工具和库(如
-
刨根问底
:
- 阅读爬虫源码(如Scrapy的调度器和管道模块),理解实现原理。
- 在实践中复现和优化已有的爬虫代码,例如自己实现页面解析逻辑。
3. 建立学习参考目标
-
短期目标
:
学习比你优秀的同龄人:
- 加入相关技术社区(如知乎、CSDN、Github),阅读爬虫案例文章,分析他们的代码风格。
-
中期目标
:
跟随领域内专家:
- 找到爬虫方向的优秀开发者或团队,关注他们的开源项目和博客(如Airbnb的开源爬虫工具)。
-
长期目标
:
学习大公司实践:
- 关注大型互联网公司(如阿里、字节跳动)在爬虫方向的工程化案例(分布式爬虫、高效数据存储)。
4. 推荐学习方式
-
以工具为线索
:
- 系统掌握工具链:从
requests到Scrapy,再到分布式爬虫工具(如pyppeteer和celery)。 - 通过项目训练:尝试构建一个多功能爬虫(如新闻聚合器),从抓取到存储、再到数据分析全流程覆盖。
- 系统掌握工具链:从
-
以专家为线索
:
- 追踪业内专家博客,了解他们在反爬和数据抓取方向的解决方案。
- 学习专家对复杂问题的分解与解决思路。
5. 学习、工作和生活的平衡
-
高效利用时间
:
- 学习时优先完成基础任务,如了解HTTP协议与工具使用;复杂任务可以分段推进。
- 使用工具简化工作:抓包分析时用Fiddler,动态渲染用
Selenium自动化脚本。
-
保持笔记习惯
:
- 用Obsidian或Markdown记录每次学习心得、代码调试过程。
- 定期整理成文档,方便复盘和查阅。
6. 解决方向缺失问题
问自己以下问题:
-
最新进展
:
- 是否了解爬虫领域最新的动态和技术趋势?如反爬对抗的最新方法(浏览器指纹识别)。
-
专家学习
:
- 是否深入研究爬虫领域专家的最佳实践和公开项目?
-
社区资源
:
- 是否关注技术社区的热门讨论?例如,Github上的爬虫仓库是否Fork过并研究?
-
工具分析
:
- 是否对
Scrapy的每个模块和扩展功能做过深入分析?
- 是否对
具体应用的行动计划
-
短期行动
:
- 完成培训班的作业内容,逐步尝试抓取真实网站数据(如豆瓣、知乎)。
-
中期目标
:
- 用Scrapy构建一个完整的爬虫项目,包括数据存储到数据库。
-
长期目标
:
- 熟悉分布式爬虫架构,探索中高级爬虫方向(如模拟人类行为应对反爬机制)。
你可以根据自己的时间表和课程内容灵活调整行动计划,最终目标是形成从学习到实践的闭环成长路径。
logging
202501111501 YJH init